
Creating Chatbot with Deep Learning
Introduction
The basic foundation of Chatbot is to giving responses to your queries. The best response will be providing the user with relevant information, asking follow-up questions and have a conversation with the user in a realistic way. Sometimes sentiments analysis is used to understand the behavior of the user based on the input user gives.
In order to understand and execute the responses required by the user, the chatbot needs to understand their intentions. It is only then it can deliver the required result by following proper grammatical and lexical format.
Since chatbots mimic an actual person, Artificial Intelligence (AI) techniques are used to build them. One such technique within AI is Deep Learning which mimics the human brain.
We can categorize AI into three categories –
- Knowledge Base: It is a database used for knowledge sharing and management. It is not merely a space to store the data but it is an AI tool for delivering decisions. Through the use of the machine, the knowledge base uses sets of rules to make its decisions.
- Machine Learning (ML): It overcomes the limitations of the straight up rules of knowledge base approach to AI. ML is able to extract the patterns from the data instead of relying on the rules. ML understands the knowledge in the real world and based on the correlation between the features the output is obtained.
- Representation Learning: When an ML model is created it must be able to learn the representation of data itself. Learned representation results in better performance than hand designed representation. Consider the example of face recognition, as humans, we can recognize faces from different viewing angles, different lighting conditions, different facial features such as spectacles or beard.
This representation of data is abstract and can be thought of as a hierarchy of simple to complex concepts which allow us to make sense of different data that we encounter.
However, this information is almost impossible to model because of the randomness. Deep Learning attempts to overcome this challenge by expressing complex representations in terms of simpler representations.
Chatbots
There are many types of chatbots based on different types of learning. Some of them are listed below:
1. Rule-Based Chatbot: The creation of this0 kind of bots are pretty straight forward. The bot is trained on some limited data and the bot can answer the questions based on that data. But the bot is not efficient to answer the questions for which the bot is not trained.
2. Retrieval Based Chatbot: When given user input, the system uses heuristics to locate the best response from its database of predefined responses. Dialogue selection is a prediction problem, heuristics in which is used to identify the most appropriate response templates to involve simple algorithms like keywords matching or else it may require more complex processing with machine learning. Nevertheless, of the heuristic used, these systems regurgitate only predefined responses and do not generate new output.
3. Generative Based Chatbot: This is an advanced kind of a chatbot which doesn’t use any pre-defined repository for any responses or the queries which the user asks to the machine. The chatbot learns everything from scratch using Deep Learning. Needless to say, a Generative chatbot is harder to be perfect. The generative model, however, does not guarantee to either appear human, however, they adapt better.
Google Assistant is using retrieval-based model. Which can help you by giving an idea of how it looks like.
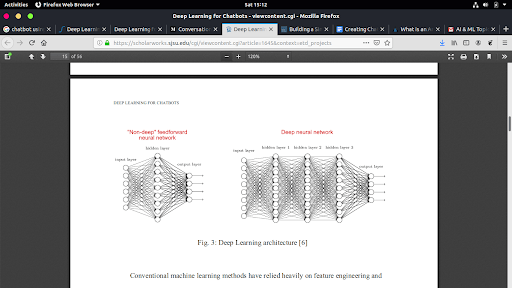
Deep Learning
Artificial Neural Network(ANN) is a computational model just like a human brain which consists of multiple numbers of neurons. Deep Learning architecture is similar to ANN but with more hidden layers and consisting more neurons which allows us to model more complex functions like our brain.
The architecture of chatbot using Deep Learning
In order to process the data, which in most cases are words, it is better to transform data into numbers, because this is how the machine will eventually need to process the data. There includes a number of processes to accomplish this. One way is by turning words into vectors to construct a new vocabulary.
For example, the word2vec system learns vocabulary from training data (the existing chats) and then associates a vector to each word in the training data. Those vectors capture many linguistic properties, for example :
vector(‘Paris’) – vector(‘France’) + vector(‘Italy’) = vector(‘Rome’)
This is one of the most convenient and relatively simple options for converting your text into vectors that your bot will be able to read and digest. Others are Tensorflow, GloVe, etc. For Architecture, there are a plethora of architectures to build, and it will depend on the needs and preferences which one to go with.
One of them is Tensorflow which comes with seq2seq module which consists of two Recurrent Network (RNN): one is encoder which processes the input and other is decoder which generates the output.
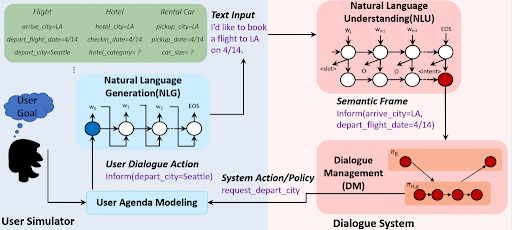
Role of NLU, NLG and Dialogue Management in Conversational Artificial Intelligence
1. Natural Language Understanding(NLU): NLU is responsible for transforming user’s utterance (which we can call as input to the machine) to a predefined semantic frame according to the system’s convention i.e. to format understood by the machine.
For example, intents can be greeting under which the keywords would be Hi, Hello, Hey, etc. An LSTM-based recurrent neural network with a Conditional Random Field (CRF) layer is used on top of NLU as NLU has a sequence tagging problem.
2. Natural Language Generator(NLU): NLG is understandable as its name. It can be taken as the reverse of natural language understanding. It transforms the output of the machine which can be understood by the end user.
3. Dialogue Management(DM): DM could be connected to any Database or any knowledge base from where it can produce some meaningful answers.
LSTM
To model longer-term dependencies LSTMs were introduced. Using a series of gates which determines whether a new input should be remembered, forgotten, or used as output. The error signal can now be fed back indefinitely into the gates of the LSTM unit. This helps overcome the vanishing and exploding gradient problems in standard RNNs, where the error gradients would otherwise decrease or increase at an exponential rate.
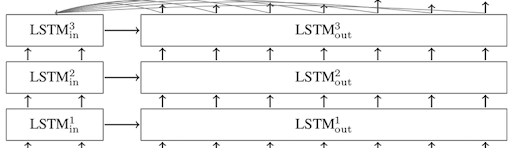
LSTM with dual-encoder working:
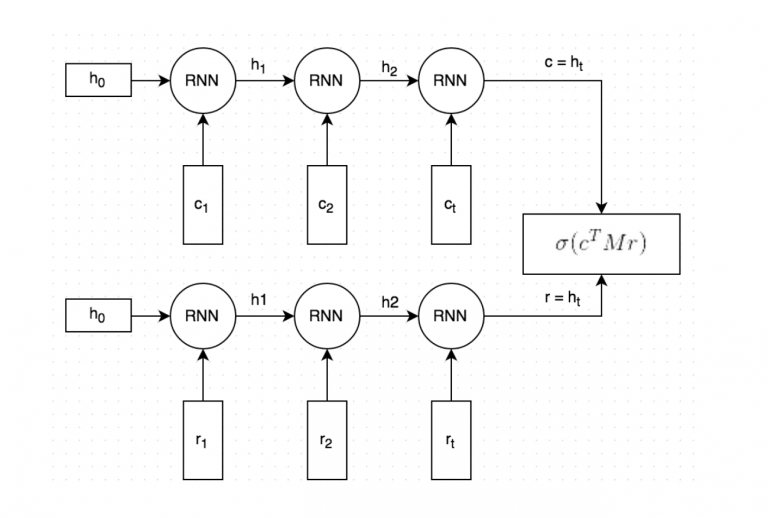
- Both the context and the answer are turned into vectors (vectors of words). This conversion occurs during the data processing phase.
- Both vectors (“embedded words”) are put into the RNN word-by-word. This gives other vectors which capture the meaning of the context and the answer (They are referred to as c for context and for an answer). You decide how large those vectors should be.
- Vector c after being multiplied with matrix M produce an answer. And matrix M cultivates during training (your weights).
- To measure the accuracy, predicted answer is compared with the actual answer.
The program applies regularisation functions (e.g., sigmoid) to convert the measurement into an actual probability.
If you’re into business and looking for augmented reality developers to increase the effectivity of your business you’re at the right place. we at Nimap Infotech have creative content developers to help you to grow your Business.
































